
ここに来てやっとですが、人工ニューラルネットワークを学習させてみましょう。
前回はある関数をある教師データに近づけるために(教師データとの誤差を最小にするために)頑張ってました。やることは人工ニューラルネットワークでも同じことです。ではニューロン1つを見てみましょう。

すごく久々なので忘れちゃった人がいるかもしれません。思い出してみましょう。
これはNこの入力を持つニューロンで、それぞれ入力値がx1からxNです。ただ、入力は単純には足し算されずに、それぞれ重み付けw1〜wNが掛け算されます。それが全て足されてsigmoid関数の入力となり閾値θ合わされて出力値yが決まります。
式で書くとこんなでしたね。
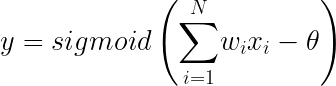
では、この1つのニューロンを学習させましょう。学習というか、変更できるニューロンの値というのは重み付けのw1〜wNと閾値θです。

つまりこれを教育するっていうことは
「あるx1x2…xNを入れた時に欲しいyが出るようなw1w2…wN」にするってことです。例えばx1にだけよく反応するようにしたければw1だけ大きなものにしたいですし、x1でもx2がきても大きなyにしたければ閾値θが小さくなるか、w1〜wNの全部が大きくなるといいですね。どっちにするか悩みどころですね。というか閾値θだけ邪魔ですね。他は綺麗に並んでるのに。なんとか重み付けであるwと同じようにシータも扱えないでしょうか。
閾値シータを重み付けに混ぜる
今閾値θはこんなふうに使われています
sigmoid( (x1・w1 + x2・w2 〜 xN・wN) – θ )
ここでθをw0として扱いたいのですが(何故そうしたいかはあとで分かります)。
こうするのはどうでしょう。

いつも1であるx0を用意しちゃってw0を用意してみました、すると
sigmoid( (x1・w1 + x2・w2 〜 xN・wN) – θ )
をx0を絶対1の入力、w0を-θとして後でθを計算するとすると
sigmoid( x0・w0 + x1・w1 + x2・w2 〜 xN・wN )
こうやって全部xとwの掛け算の形で表せられました。つまりこのニューロンは
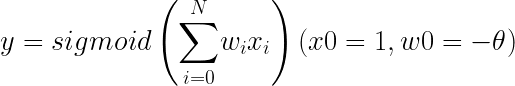
ということで、学習というのはw0~wNの値を決める作業ということになります。
これでちょっと簡単になった。
評価関数
では、これを学習させましょう。理想は「教師データと同じ結果を出すようなw0~wN」ということです。評価は教師データと実際に計算した値とのズレが小さいことです。だから、手元に教師データの入力値を入れて計算したy(i)と、その時の理想的な値であるY(i)を使うとその誤差は
E(w0,w1,,,,wN) = (Y(i) – y(i))^2
こうやって表せられます。(なんで2乗するかは前回やりました)
評価関数Eはw0〜wNの関数になっています。
当たり前ですね。w0だけいい感じに合わせても他がダメなら誤差だらけです。
これを小さくしたいんですが、じゃあどうやってこれが小さくなるように調整すればいいんでしょう。「大きすぎるな」「小さすぎるな」って時に一体どのwをいじればいいんでしょうか。
大きい物ほど小さく
もちろんどのwの値をいじっても結果を修正することが出来ますが(xが0でなければね)、ただ選ぶことが出来ません。どうするかというと
全部いじる
のです。
大事なことですが、結局誤差を表す評価関数を0にしたいわけじゃなくて小さく出来ればいいんです。別に算数みたいに一発で教師データに合うように調整する必要は全くないんです。
ということで結果が大きかったならwを全体的に小さく。逆に小さかったらwを全体的に大きくすればいいんです。
ただ、これだとwが全部同じ値になっちゃうので大きな入力があるやつほど大きく変えてしまうというやり方をします。
イメージなんですが、結果が大きすぎるときに、例えばこんな感じでx1だけ他に比べて大きかったとします。

この時に、入力がでかいやつほど、その分重み付けwを小さくすることで調整します。
こんなイメージ。

もちろん、他のw2やw3も小さくします。1つだけ選ぶということではありません。結果が大きいとわかった時には入力の値に応じてwを”全て”小さくします。ただ「うるさいやつほどボリュームを下げる」ということです。
どのぐらい変えてやればいいのか
大きいやつほど小さくしたいとして、単純にi番目の重み付けwを
wi = wi – x*0.0001
とかで小さくすれば入力であるxの大きさに応じてwiを小さくすることが出来ます。これもありです。これを全てのwに行うっていうのを沢山の教師データ使ってやる。どうせ、一発でwiを決めなくても良いのですから。1回ごとに正解に近い答えを出せるwiに近づけばそれでいいんです。0.0001を小さめにしてちょっとずつちょっとずつ動かせば安心ですよね。計算を何度もやることで目的のwiにすることが出来ます。
ただそのやり方は「w0もw1も誤差に対する影響が同じぐらい」という前提に立っています。しかも「誤差が大きくても小さくても動かす大きさが一定」です。
これだとよくないので、早く答えにたどり着くためにも誤差の大きさなども考慮しましょう。
wiがどのぐらい誤差に影響するのか
評価関数は
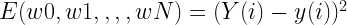
でした、この関数はw0〜wNの全てに影響を受けます。じゃあi番目の教師データを使ってる時の誤差に対して、n番目の重み付けwn(さっきまでiでしたが、i番目の教師データっていうのでiを使っているのでnにします)がどのぐらい影響をおよぼすのか。誤差を表す評価関数をwnで偏微分してみましょう。

そして、sigmoid関数は微分可能なので、微分しちゃいます(シグモイド関数 微分 とかでググってください)

このような形になります。ここでやっとニューロンにシグモイド関数を使った意味が出てきます。
微分した式に出てくるのは微分する前の計算結果y(i)や理想的な値であるY(i)、それにi番目の教師データのn個目のXn(i)ぐらいなもんで、難しい計算がないのです。
これだけでwnがi番目の教師データの時の誤差に与える影響(つまり偏微分値)が分かります。
これが得られればこれを指標にしてwnを変更しましょう。勾配法的にやると

と、wnをwnの偏微分値と小さな何かの値を使って更新します。(長かったのでE(w0,w1,,,wN)をEにまとめました)この偏微分値にさっきのを入れると。
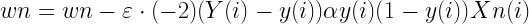
となります。ところで、
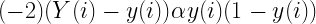
の部分はi番目の教師データが決まれば決まる値でnが何であれ関係ありません。これをAとでもしておくと
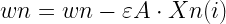
となります。これは教師データからAを計算できればそれを元にwnをどのぐらい修正すればいいのかがわかります。
ちょっとまとめにはいりますが、具体的にこれをつかってどうやって学習させるかというと
- w0~wNを適当に最初決める(これでx0~xNを入れると結果が計算できる)
- εを適当な小さな値の何かに決める。
- i番目の教師データを使ってAを計算する
- Aとεをつかってw0〜wNを全て修正する。
これを繰り返すわけです。
結局wnの誤差に対する影響度を調べるために偏微分とかの計算したものの、結局Aという固定な結果になって「w1だろうがwNだろうが影響度は同じ」ということになりました。そういう意味では
wn = wn – xn(i)*0.0001
とほぼ同じ結果です。0.0001がεAという値になっただけです。
ただし、Aは教師データによって変わってきます。誤差が大きければそれだけAも大きくなるので単純に0.0001とするよりはより早く答えに近づきます。
まとめ
- 人工ニューラルネットワークの1素子も教師データで学習させられる
- 閾値は1つの入力として捉える
- 誤差を元に閾値を変えていくが、うるさいやつほどボリュームを下げる
コメントを残す
コメントを投稿するにはログインしてください。