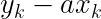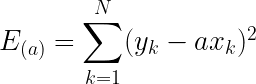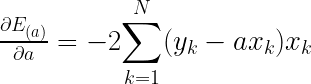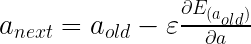nRF51822はBLEの利用できるNordicのチップですが、ソフトデバイスと呼ばれるNordicの用意しているプログラムを利用することで簡単にチップからBLEのadvertisingを出せたりします。
そのソフトデバイスにはいくつか種類がありますが、違いはCentralになるかPeripheralになるかです。
S110はPeripheral用のソフトデバイスです。(CentralはS120で、両方ってのがS130)
S110自体はNordicのサイトからhexファイルでダウンロードできます。
また、KeilのCMSISにS110を使うためのもろもろが用意されているので今回はCMSISを使ってプロジェクトを作り、とりあえずAppleのiBeaconと同じパケットを出して見るところまでやってみます。
Keilを開く
ではプロジェクトを作りましょう。
ターゲットを nRF51822xxAAでプロジェクト作成します。
CMSISにS110を追加。まずCMSIS管理画面で
nRF_SoftDevice, nRF_Libraries, nRF_Drivers, nRF_BLE, それにnRF51822のデバイスのものをInstallします。それから、このプロジェクトにS110を追加し、関係するファイルも追加します(Resolveを押すと関係したファイルを一斉に追加してくれます)
終わるとこんなかんじになるはず

あとはプロジェクト設定です。S110とフラッシュに同居するのでROMやRAMの設定が必要です。
プロジェクト設定にて
Xtalを16
ROMを0x16000 – 0x29000
RAMを0x20002000 - 0x6000
UseMicroLibにチェック
プロジェクト設定 C/C++
Defineに
NRF51 BLE_STACK_SUPPORT_REQD S110 SOFTDEVICE_PRESENT
MiscControls に
–c99
ASMにも同じdefine
プロジェクト設定 Linker
Use memory layout from target dialog
プロジェクト設定 Debug
DebuggerにJLINKを指定。
DebugSetting
SettingでPortをJTAGからSWにする
FlashDownloadのRAMは
0x20000000 – 0x2000
ResetAndRunにチェック入れると便利
プログラム
プログラムは
https://github.com/yuki-sato/nRF51822-S110-v7-iBeacon/
に用意しました。
NordicのS110の別のチップ用だったサンプルを流用したものです。
main.c以外にめんどくさがりな貴方のために、プロジェクトやCMSISもそのまま置いてありますから、これをCloneしてきたらすぐにフラッシュ書き込みしてiBeacon出せるはず。
ちなみにライターは勝手にJLinkでマイコンとつないでることにしてますが、そういう人多いはず。
その場合はこれで問題なくフラッシュ書き込みできるはず。
S110を書き込むのは忘れないように。nRFGoで書き込んでくださいね。
S110を書き込むときの注意
S110を書き込むときにはまず
最新のnRFGoを使う
ことを忘れないで下さい。そうじゃないとv7のS110は書き込めません
あと、まだ詳しく調べられていないのですが、protectionのチェックをはずさないと途中でエラーで割り込まれてしまいます。エラー割り込みの引数
uint32_t error_code, uint32_t line_num, const uint8_t * p_file_name
それぞれ 2 0 0 となる感じで。同じ症状の人はprotectionを外しましょう。


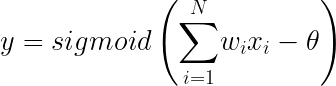


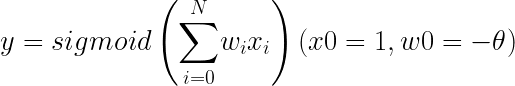


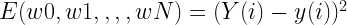



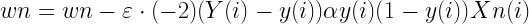
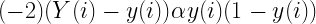
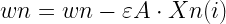
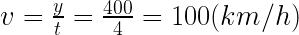
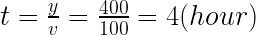
 くさんあります。ちなみに物理の世界ではものが動くことを「ものが運動する」というので今後は”動く”とか”動き”の代わりに”運動”を使うことにしましょう。さて、だんだん速くなることを「加速する」って言いますよね。今回は加速する運動について考えます。さて、ここにだんだん速くなる箱を用意しました。同じペースで速くなるようで、こいつの運動を1秒ごとに観察するとこうなりました。この箱の加速の大きさ、つまり、加速度を考えてみましょう。
くさんあります。ちなみに物理の世界ではものが動くことを「ものが運動する」というので今後は”動く”とか”動き”の代わりに”運動”を使うことにしましょう。さて、だんだん速くなることを「加速する」って言いますよね。今回は加速する運動について考えます。さて、ここにだんだん速くなる箱を用意しました。同じペースで速くなるようで、こいつの運動を1秒ごとに観察するとこうなりました。この箱の加速の大きさ、つまり、加速度を考えてみましょう。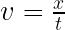



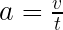



 )のロケットが打ち上げられました。打ち上げ10秒後の速度は?
)のロケットが打ち上げられました。打ち上げ10秒後の速度は?